Excel設計・システム化の基礎~上級【テーブル×Power Queryでデータ再利用】

「一度作ったExcelなのに、
「マスタデータをコピペしており、
「数式が入ったセルを誰かに壊され、
Excel(エクセル)
この記事では Excelのテーブル設計 を基軸とした設計方法・システム化の方法について解説します。
具体的には、
必要に応じてこれらの場所を分割することが重要です。
Excelを「ただの計算表」
目次
見た目重視でExcelブックを作成した場合、
-
再利用するのに手作業・複雑な関数が必要:
見た目を整えるための セル結合や単位の混在 などを使ってデータを格納すると、データの再利用性が落ちます。
フィルタや並べ替えのようなExcelの標準機能を正常に動作させるために、手作業や複雑な関数が必要になります。 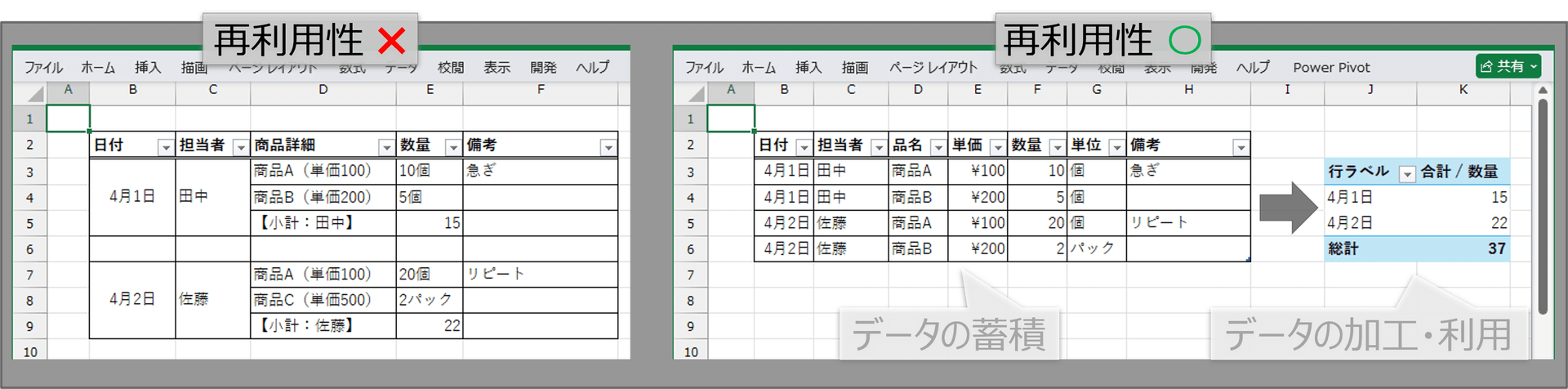
-
コピペによりデータが散乱:
データをブックごとにコピペ して使用していると、どれが本当の情報なのかわからなくなります。
マスタデータの場合は特に深刻で、修正時にどのブックを直せばよいかわからない、
修正しても古いデータを参照してしまう、という問題が起きます。 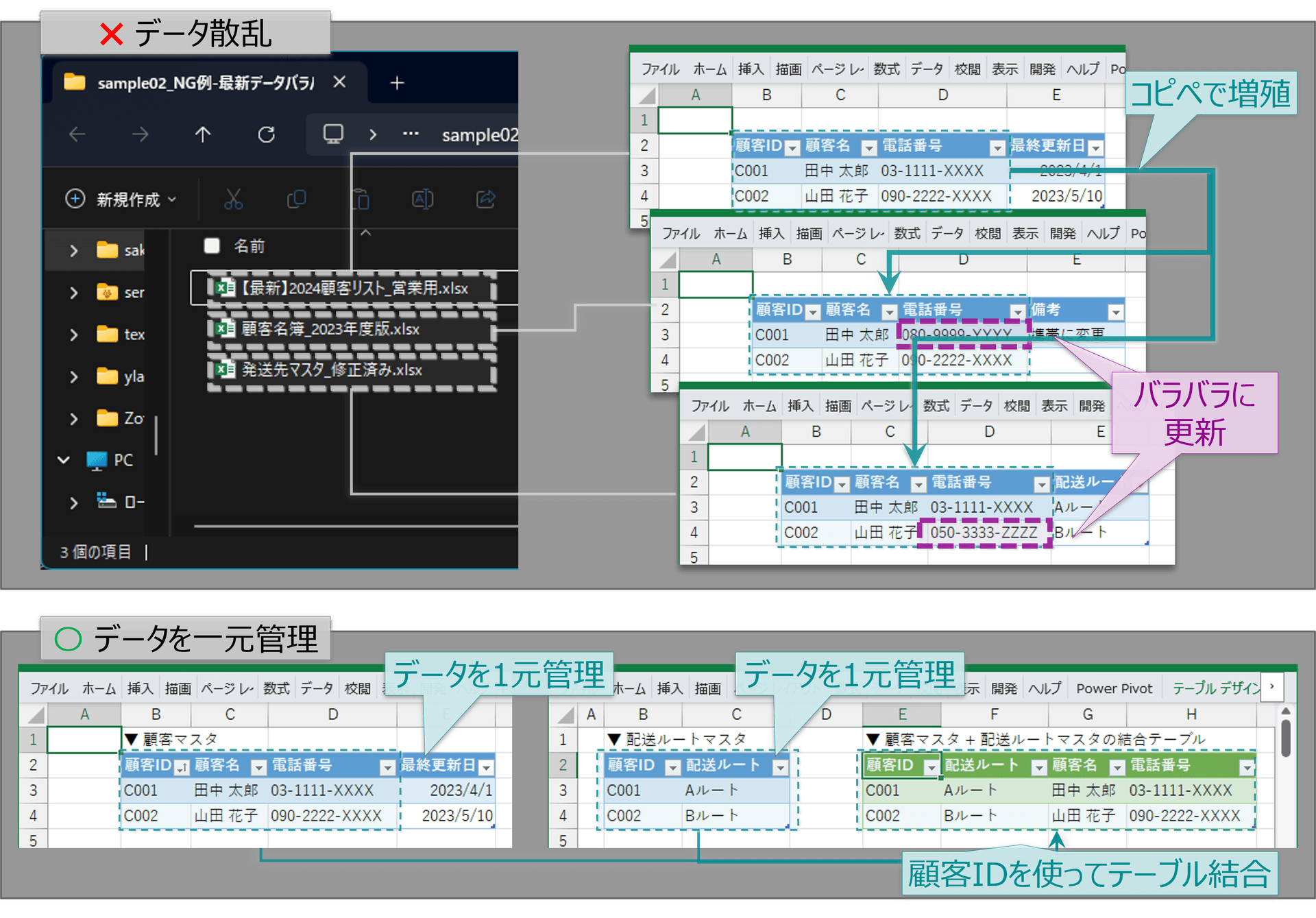
-
データの書き換え場所がわかりづらい:
入力欄と計算セルが混在していてどこを書き換えればよいかわかりづらいと、
ユーザーが誤って 計算式を数値で上書き してしまい、ロジックが破壊される事故が多発します。
ブックの作成者にとっても、パッと見で判断できなければ解析作業に時間を要することになり、 無駄な工数が発生します。 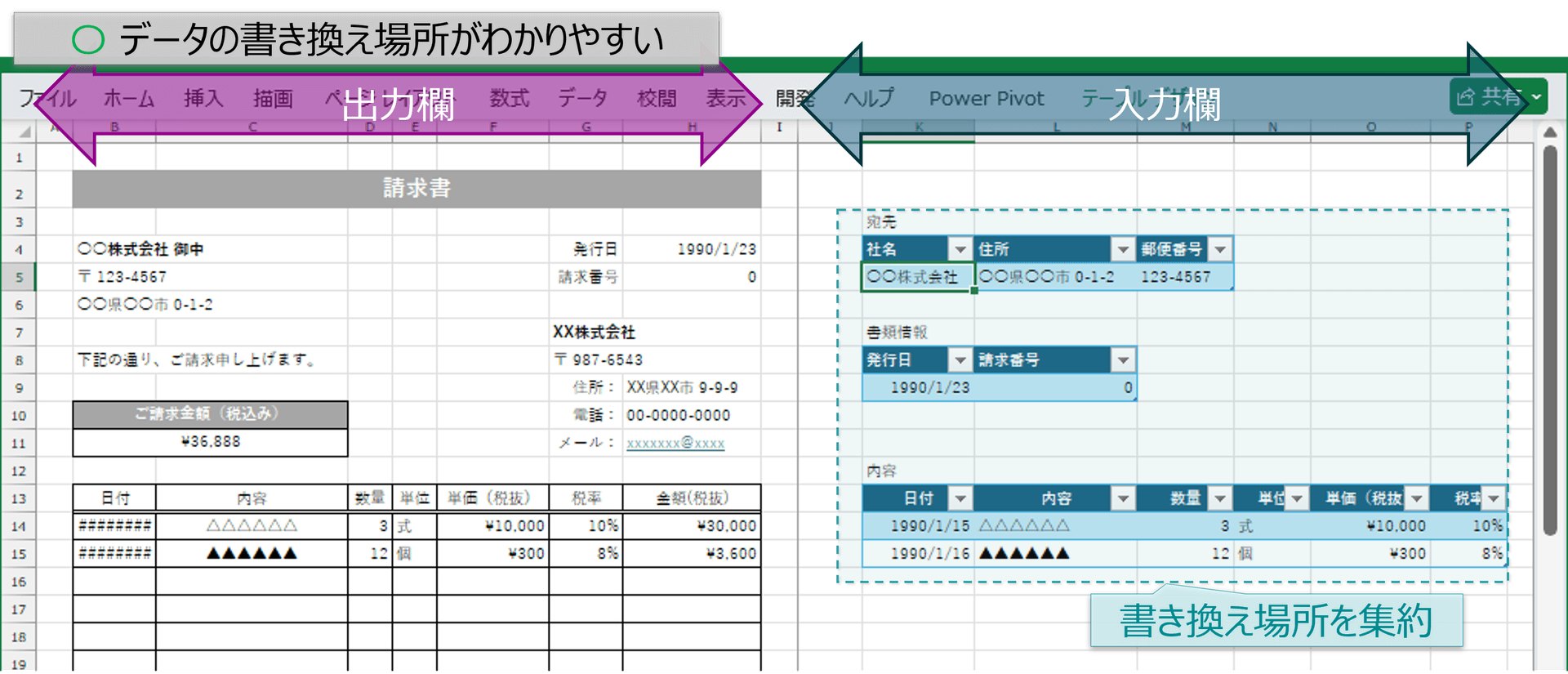



「データの蓄積・加工・活用」
Excelを「使い捨てのファイル」
データを使う流れは「蓄積・加工・活用」
逆に、
データの利用は「蓄積・加工・活用」

一般的に、
-
データの蓄積(入力・保存)
: Excelテーブル 情報システムにおける「データベース」
の役割を担う。
再利用性を確保するために、一貫性のあるテーブル形式を維持し、 データを構造化することが重要。 -
データの加工(計算・変換)
: Power Query・関数 蓄積されたテーブルをソースとして抽出し、
目的に応じた整形を行う「処理エンジン」 として機能する。
データをテーブル化することでPower Queryによる自動認識が可能となり、更新操作のみで最新状態を反映できる。 -
データの活用(表示・出力)
: レポート・UIなど 加工済みのデータを、
利用者が意思決定や確認を行うために最適化された「UI(表示画面) 」 として出力する。
データを 加工 し 活用 するためには、
「DATAとVIEWの分離」
「データの蓄積・加工・活用」
- 「データと閲覧(DataとView)
の分離」 - 「DOV(Data-Operation-View)
パターン」 - システム開発の「三層アーキテクチャ/MVC(Model View Controller)
モデル」
に近い考え方です。
ただし、
データを再利用しやすい形で「蓄積」
蓄積したデータをそのままの状態では「活用」
なぜ「データの蓄積(テーブル設計)
「データの 蓄積 」
- 「加工」
の自動化が容易になる: データがきれいにテーブルにまとめられていれば、 複雑なデータクレンジングや統合を必要とせず、 「データの加工」 を簡単に自動化できます。
テーブル単位の加工はPower Queryで加工しやすいです。 - 「活用」
のバリエーションが広がる: 1つの蓄積データは複数の用途に使い回せます。
データを1か所修正するだけで、「請求書」 「月次推移表」 「グラフ」 など、 すべてのデータの利用先に一括で変更を反映できます。 - データの信頼性が担保しやすい: 計算ロジックを蓄積データから切り離しやすく、
入力場所を明確にできます。
不意の操作ミスによるデータ消失リスクを下げられます。

例)
- 蓄積: Excelテーブルで売上明細データを管理
- 加工: テーブルを参照し、
Power Queryで顧客別に集計・整形 - 活用: 請求書、
月次レポート、 売上推移グラフなど用途に合わせて出力
逆に、
テーブル設計を基軸にした設計:向いているケースと不向きなケース
必ずしもテーブルを活用した「データの蓄積」
向いているケース
- データを継続的に蓄積する業務:
日々の売上やログなど、時間の経過とともに増大する情報を管理する場合 - 繰り返し使う帳票・レポート:
月次報告書のように、同じ体裁でデータを更新し続ける必要があるもの - 複数人で扱うExcel:
操作ミスによる数式破壊を防ぎ、誰でも同じ結果を得られる堅牢性が求められる場合
向いていないケース
- 一度きりの単発作業:
設計に時間をかけるよりも、その場で直接作成した方が早い小規模なタスク - 数十行レベルの簡易データ:
役割の整理による管理コストが、運用のメリットを上回る場合
「データの蓄積」
データの 蓄積 方法(テーブル設計)
» Excelテーブルの基本と活用法|通常の表との違い・できることを徹底解説
Excelを「再利用できるシステム(データベース)
- 構造化データの要件を満たす:「セル結合をしない」
「1行1件」 など、 機械が処理しやすい入力ルールを守る。 - 整然データ(Tidy Data)
の原則に従う:再利用やピボットテーブルでの集計が容易な構造(1セル1データ、 変数は列、 観測は行) にする。 - マスタとトランザクションを分離する:売上(イベント)
と商品情報(属性) を別テーブルに分け、 スタースキーマの形で連携させる。
これらの「テーブルの正しい作成手順」
» Excelでデータベースの作成方法|データ管理の基本ルールから限界まで解説
本記事ではこれ以降、
テーブルの配置場所:同一シート・別シート・別ブック
複数のテーブルがある場合や、
使い分けの指針
- 同一シート: テーブルサイズが小さく、
データ数がほとんど増えない場合 - 別シート: データ数が増える可能性が高い場合
- 別ブック: マスタデータなど、
他のブックからも再利用する可能性が高い場合
テーブルとして正しく蓄積されたデータは、
「加工」
この章では 関数・Power Query・Power Pivot の使い分けを中心に、
- 手法の選択 :関数・Power Query・Power Pivotの使い分け
- データの横結合 :リレーション・紐づけ・関連付け
- データの縦結合 :積み上げ・ユニオン
- 応用 :【データ活用の基本の型】外部ブックからの転記/データベース利用の基礎
手法の選択:関数・Power Query・Power Pivotの使い分け
データの加工手法には以下の2つ(+α)
- 関数(数式)
: セル単位でデータ加工を行う。 即座に計算・表示するリアルタイム性に優れる。 - Power Query: テーブル単位でデータ加工を行う。
外部データの取り込みや大量データ処理に強い。 - (Power Pivot)
: ピボットテーブル向け。 大量データの扱い、 複数のテーブル間の関係づけ(リレーションシップ) を構築できる
基本的には関数(数式)
【Power Queryの使いどころ】
- データが外部にある : 参照するデータが外部ファイルや複数ブックにまたがる場合
- 処理が複雑: 関数では記述が困難・複雑になる多ステップの加工やクレンジングが必要な場合
- データ量が膨大: 数万件を超えるような大量データの処理を行う場合
- 出力先サイズを自動調整 : 加工後の結果出力先で、
行・列の挿入を自動で行いたい場合
データの横結合:リレーション・紐づけ・関連付け

複数のテーブルのデータを横方向に結合・関連付けする方法は以下の3つです。
- XLOOKUP / VLOOKUP / INDEX-MATCH 関数:単一の参照向け(リアルタイム更新重視)
- Power Query マージ:2つのテーブルの結合向け
- Power Pivot リレーションシップ:複数テーブルの結合向け(大量データ向け)
テーブル間の関連付けは、
データの縦結合:積み上げ・ユニオン

複数のテーブルのデータを縦に結合する方法は以下の2つです。
-
VSTACK関数:同一ブック内の複数シートの結合、
リアルタイムView用 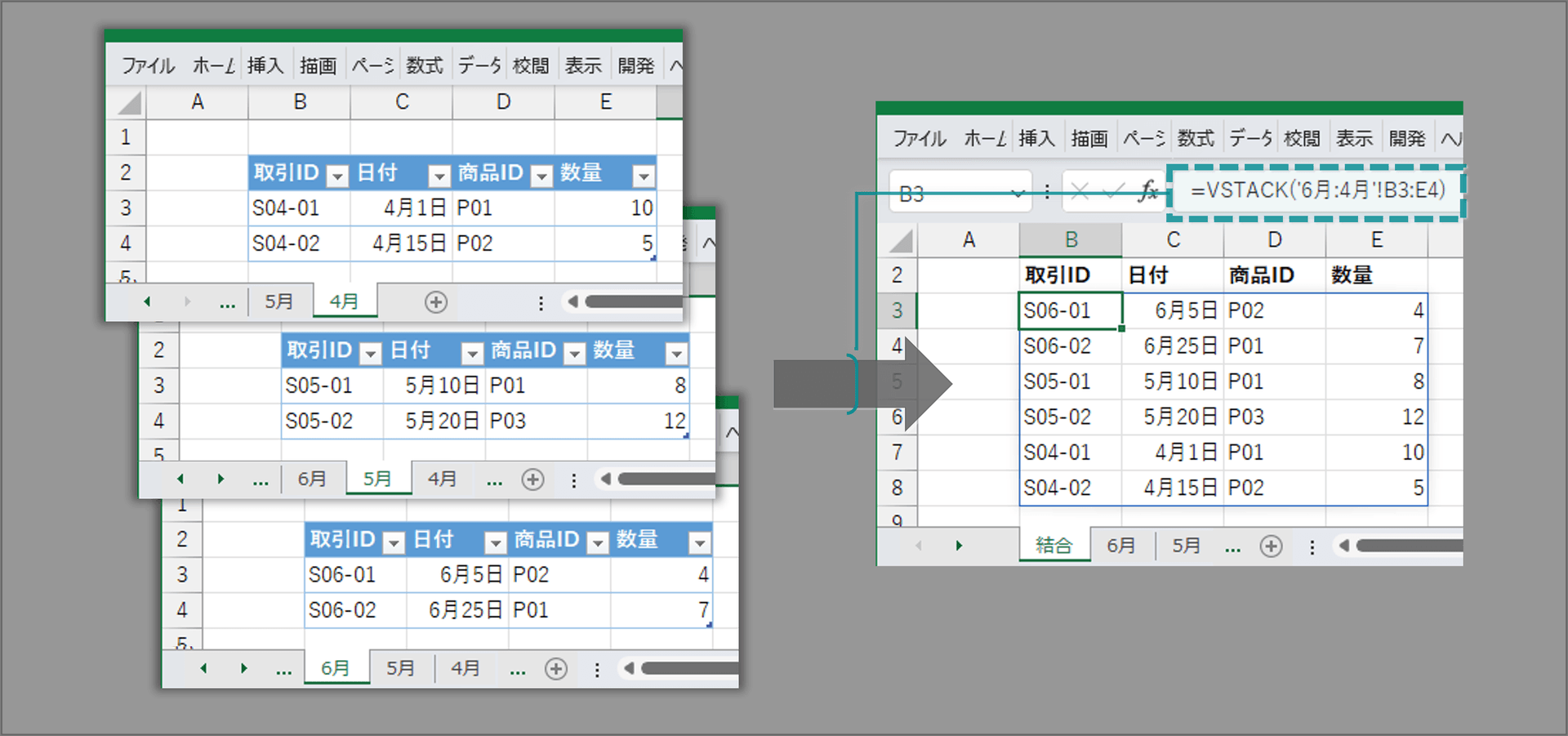
-
Power Query 結合:複数の外部ブックの統合、
内部・外部テーブルの結合 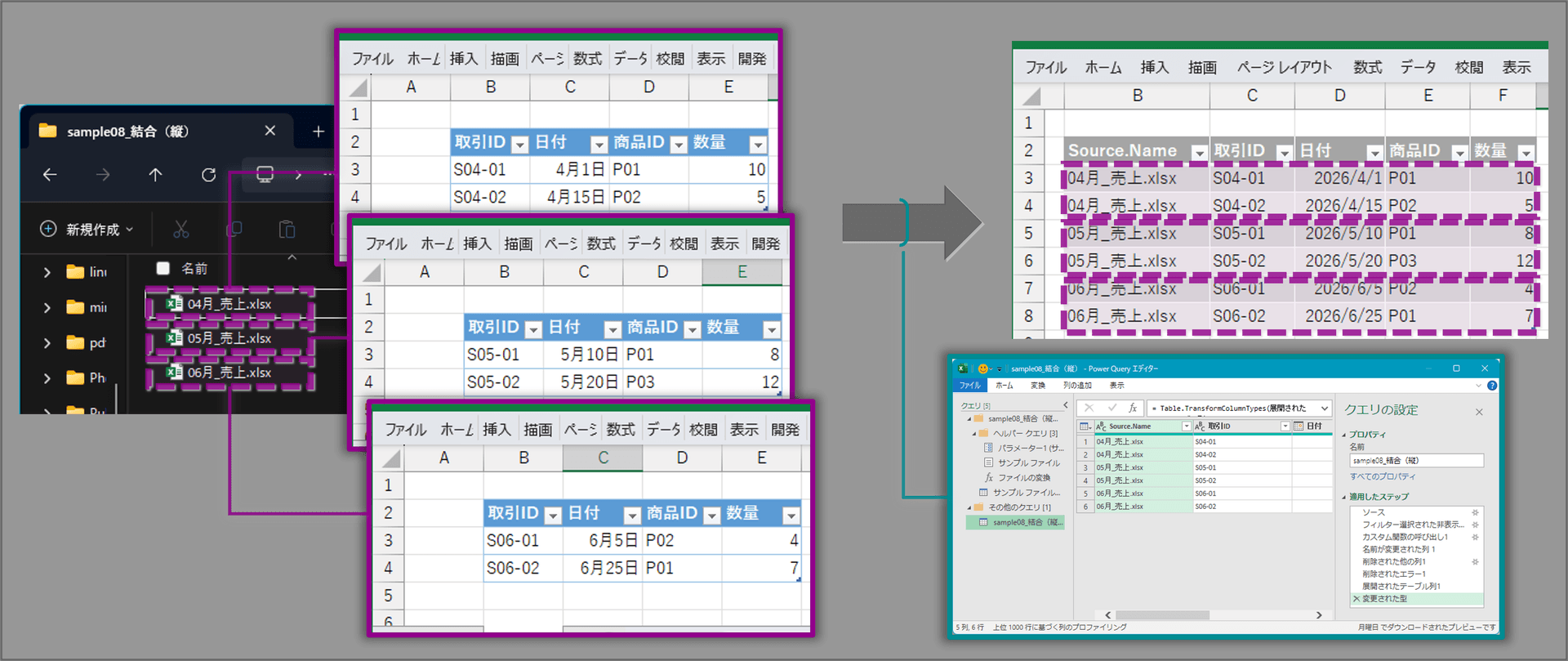


応用:【データ活用の基本の型】外部マスタからの転記/データベース利用の基礎
データ活用の基本は 「1つのデータを使い回すこと」
下記の通りにPower Queryと関数を使うと実装方法のベースが作れます。
- マスタデータを1つのブックに切り出す(データの 蓄積 )
。 - マスタデータをPower Queryで外部参照し、
ブック内にテーブルとして配置する。 - ※ この段階でPower Queryを使ったデータ 加工 をしても良い。
- ※ この段階でPower Queryを使ったデータ 加工 をしても良い。
- 関数やPower Queryを使い、
ブック内でデータを 加工 し、 活用 する。
外部ブックの参照にはPower Queryを使い、

マスタテーブルの作成から、
データの 活用 とは、
- ① 出力 :データをそのまま使う
- ② 入力支援 :ミスを防ぐ・操作させる
- ③ 可視化・分析 :判断させる
① 出力:数式やPower Queryでデータをそのまま使う
加工 したデータをそのまま出力する方法には、
- セル値 : 数式(関数)
による出力。 単一の計算結果や抽出した値を特定のセルに配置して表示する。 - テーブル(リスト)
: Power Queryによる出力。 抽出条件に合致する複数のデータを一覧形式(Excelテーブル形式) で表示する。 並び替えやフィルタ機能がすぐ使える。

これらは再度、
応用例:書類フォーマット
フォーマット・枠組みとなるシートを作成し、

応用例:縦型のリスト・カード型表示
Excelテーブルでは、
テーブルの中から特定の項目だけを抽出し、
【XLOOKUP使用:表示する項目を個別に指定】
=XLOOKUP($C$2, テーブル1[ID], テーブル1[商品名])
=XLOOKUP($C$2, テーブル1[ID], テーブル1[カテゴリ])
=XLOOKUP($C$2, テーブル1[ID], テーブル1[ブランド])
=XLOOKUP($C$2, テーブル1[ID], テーブル1[発売日]) 表示項目をセル値から指定する場合
INDIRECT関数を併用すると、
=XLOOKUP($C$2, テーブル1[ID], INDIRECT( "テーブル1["&$B4&"]" ))
【FILTER + TRANSPOSE使用:条件に合う行全体を抽出し、
=TRANSPOSE(FILTER(テーブル1, テーブル1[ID]=$C$2))
フォーム機能
Excelには、

※ オプションのリボンのユーザー設定から、
② 入力支援:ドロップダウンや書式でミスを防ぐ
以下の方法を用いると、
- データの入力規則(ドロップダウンメニュー)
:選択肢をマスタから取得し、 入力値の表記揺れや誤入力を物理的に防ぐ - 条件付き書式(視覚フィードバック)
:特定条件に合致するセルを自動で色付けし、 エラーや状態の把握をしやすくする

③ 可視化・分析:ピボットテーブルとグラフで判断を促す
以下の方法を用いると、
- ピボットテーブル: データをクロス集計し、
多角的な分析を動的に行う - ※ 通常のセル範囲/テーブルやPower Query/Power Pivotを使ったデータモデル経由でも作成可能
- グラフ: 数値データを視覚化し、
傾向や異常値を一目で判断できるようにする - ※ ピボットグラフでなく通常のグラフの場合は、
一度セルやテーブルを経由する必要あり
- ※ ピボットグラフでなく通常のグラフの場合は、

ピボットテーブルは
Excelブックをシステムとして運用するために役立つ機能・テクニックとして、
- 誤操作防止 :ロジックが破壊されないための誤操作防止
- 作業レイアウトの設定 :頻繁に行き来する作業を効率化する工夫
- パフォーマンス最適化 :データ数が多い場合のExcelの動作遅延の改善策
1. 誤操作防止:保護と非表示でロジックを守る
ロジックの破壊を防ぐ、
- 保護・ロック : 計算式が記述されたセルやシート全体を保護し、
ユーザーによる誤った上書きを防止する - 非表示シート : 中間計算やマスタデータ用のシートを隠し、
ユーザーの混乱や誤操作を防ぐ - セルの非表示 : 計算過程で必要な数式などを隠し、
表示画面をクリーンに保つ
2. 作業環境の整備:複数ウィンドウによる効率化
データの 蓄積 と 加工・活用 を分けた場合、
これを防ぐためには、
表示タブの新しいウィンドウを開く > 整列から設定できます。
3. パフォーマンス最適化:動作遅延を防ぐ計算設計
データ量が多い場合など、
- 関数(数式)
からPower Queryに置き換え : 大量のデータに対し同じ計算処理を行う場合、 関数ではなくPower Queryで処理することでパフォーマンスが向上する - データモデル(仮想テーブル)
活用 : 大量のデータをすべてシートに展開せずメモリ上でのみ保持し、 必要なときだけ計算・表示することでパフォーマンスが向上する - 揮発性関数を避ける : INDIRECT、
OFFSET、 TODAY、 NOWなどの揮発性関数は、 頻繁に再計算を行うため使用を避ける
この記事では、
データを使う流れは「蓄積・加工・活用」
- データの蓄積(Excelテーブル)
:
整然データの原則に従い、構造化されたテーブルとして管理する。
マスタとトランザクションを分離し、スタースキーマを基本とした設計が実務では現実解。 - データの加工(関数・Power Query)
:
テーブルを起点にすることで、更新操作だけで最新状態を反映できる加工の自動化が実現する。
外部ブックの参照や大量データ処理にはPower Queryが有効。 - データの活用(レポート・UI)
:
1つの蓄積データを、請求書・月次レポート・グラフなど複数の用途で使い回せるようになる。
完璧な設計を最初から実現する必要はありません。
「そもそもExcelに向いていないタスクがあるのでは?」